Gumbel AlphaZero 소개 및 기본 탐색 알고리즘
📑 Table Of Contents
- 1. ⚙ Gumbel AlphaZero란?
- 2. ⚙ DeepMind Mctx: JAX 기반 MCTS 라이브러리
- 3. ⚙ 기존 AlphaZero의 한계
- 4. ⚙ Gumbel AlphaZero의 혁신
- 5. ⚙
visualization_demo.py로 이해하는 탐색 알고리즘 - 6. 🏁 마치며

1. ⚙ Gumbel AlphaZero란?
Gumbel AlphaZero는 기존의 AlphaZero가 가진 강화학습의 한계를 개선하기 위해 제안된 새로운 알고리즘입니다. 특히 적은 수의 시뮬레이션만으로도 정책(Policy)을 이론적으로 개선할 수 있다는 강력한 장점을 가집니다.
이 글에서는 Gumbel AlphaZero를 도입하는 과정 및 그 핵심 개념과 알고리즘을 정리합니다.
2. ⚙ DeepMind Mctx: JAX 기반 MCTS 라이브러리
Gumbel AlphaZero를 비롯한 최신 탐색 알고리즘들은 딥마인드에서 개발한 Mctx 라이브러리를 기반으로 구현되는 경우가 많습니다. Mctx는 JAX 기반으로 작성되어 Python 환경에서 높은 성능과 유연성을 제공하는 MCTS(Monte Carlo Tree Search) 라이브러리입니다.
2.1. Mctx 소개
Mctx는 MuZero와 같은 강력한 강화학습 알고리즘을 연구자들이 더 쉽게 사용하고 발전시킬 수 있도록 돕는 것을 목표로 합니다. C++ 등으로 작성된 기존의 고성능 탐색 라이브러리와 달리, JAX를 사용하여 Python의 편의성을 유지하면서도 컴파일을 통한 성능 최적화가 가능합니다.
2.2. 환경 구축
이 글의 예제 코드를 실행하기 위해, WSL2 Ubuntu 22.04 환경에 Miniconda를 설치하고 mctx라는 이름의 Conda 가상환경을 생성합니다.
# Conda 가상환경 생성 및 활성화
conda create -n mctx python=3.11
conda activate mctx
visualization_demo.py의 탐색 트리 시각화에 필요한 Graphviz와 pygraphviz를 설치합니다.
# 1. 시스템 라이브러리 설치 (Graphviz)
sudo apt-get update && sudo apt-get install -y graphviz graphviz-dev
# 2. Conda 패키지 설치 (pygraphviz)
conda install conda-forge::pygraphviz
마지막으로 JAX, Chex, Mctx를 pip으로 설치합니다.
# 3. Pip 패키지 설치
# JAX (NVIDIA GPU 환경)
pip install "jax[cuda12]"
# JAX (CPU 환경, GPU가 없는 경우)
# pip install jax
# Chex 및 Mctx
pip install chex mctx
# 또는 GitHub에서 직접 최신 개발 버전 설치
# pip install chex git+https://github.com/google-deepmind/mctx.git
3. ⚙ 기존 AlphaZero의 한계
AlphaZero의 강화학습은 UCT(Upper Confidence bounds for Trees) 알고리즘을 사용하여 탐색을 수행하고, 그 결과(방문 횟수)를 바탕으로 정책을 개선합니다. 하지만 이 방식은 시뮬레이션 횟수가 충분히 많지 않을 경우, 학습이 우연히 샘플링된 행동에만 의존하게 되어 정책 개선을 이론적으로 보장할 수 없는 문제가 있었습니다.
이는 곧, 제한된 시간 안에 최적의 수를 찾아야 하는 실제 대국 환경에서 약점으로 작용할 수 있습니다.
4. ⚙ Gumbel AlphaZero의 혁신
Gumbel AlphaZero는 루트 노드(탐색의 시작점)에서 PUCB(Polynomial Upper Confidence Bound) 대신 Gumbel-Top-k라는 새로운 기법을 사용합니다. 이를 통해 더 적은 시뮬레이션으로도 정책이 개선될 것임을 이론적으로 보장합니다.
또한, 탐색 과정에서 순차적 반감법(Sequential Halving)을 함께 사용하여 제한된 시뮬레이션 예산을 가장 유망한 후보 수에 효율적으로 배분합니다. 이 두 가지 핵심적인 변화를 통해 Gumbel AlphaZero는 기존 AlphaZero보다 효율적이고 안정적인 학습을 가능하게 합니다.
5. ⚙ visualization_demo.py로 이해하는 탐색 알고리즘
Mctx 공식 저장소에는 Gumbel AlphaZero의 동작을 시각적으로 보여주는 visualization_demo.py 예제가 포함되어 있습니다. 이 코드는 Mctx의 핵심 정책 중 하나인 gumbel_muzero_policy를 사용하여 탐색을 수행합니다.
visualization_demo.py를 실행하면 탐색 과정이 시각적으로 보여지며, 탐색 결과는 /tmp/search_tree.png에 저장됩니다.
출력 예시:
Starting search.
Selected action: 1
Selected action Q-value: 10.666667
Saving tree diagram to: /tmp/search_tree.png
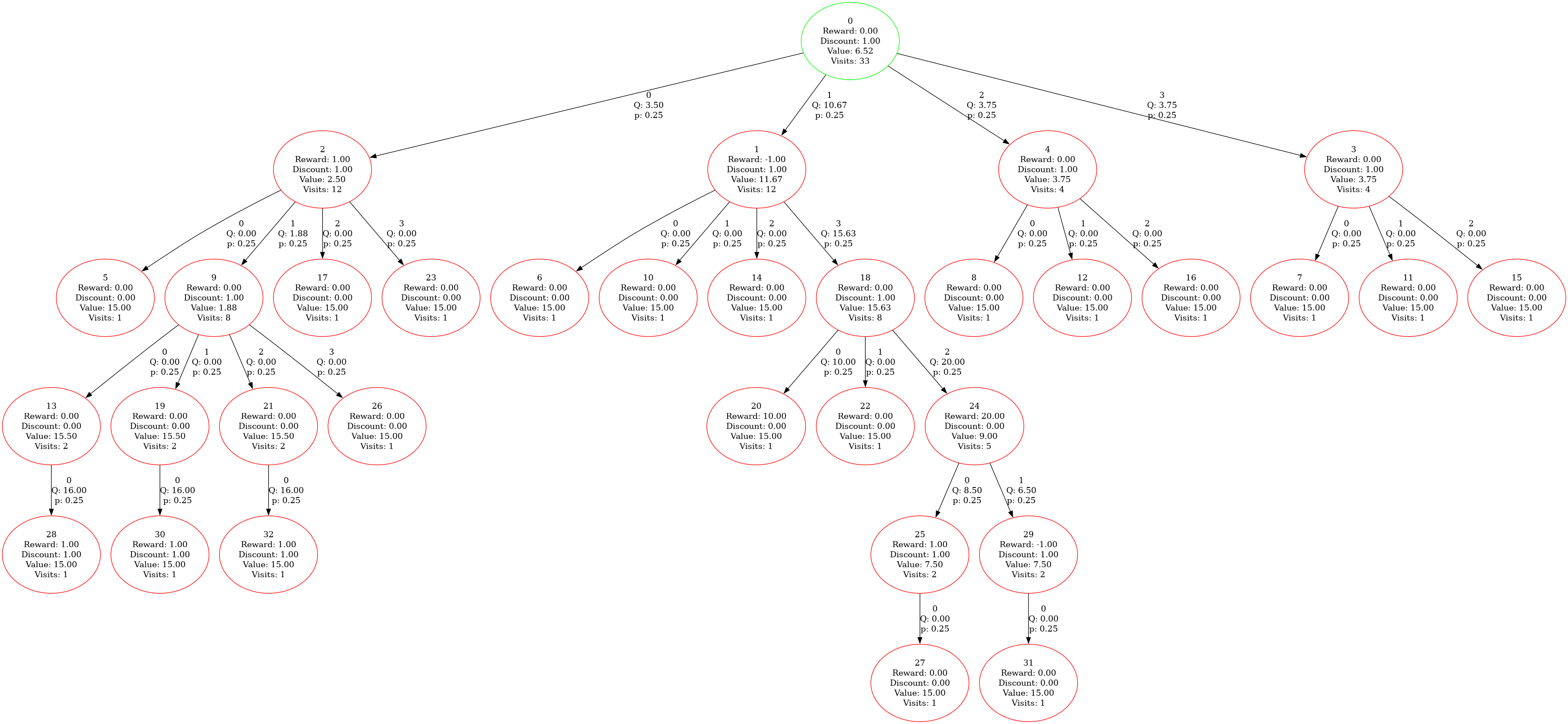
5.1. Mctx의 핵심 구성 요소
Mctx의 정책 함수를 사용하기 위해서는 사용자가 몇 가지 구성 요소를 직접 정의하여 제공해야 합니다. 이는 Mctx가 특정 게임이나 환경에 종속되지 않고 범용적으로 사용될 수 있도록 설계되었기 때문입니다.
RootFnOutput: 탐색을 시작하는 루트 노드의 상태를 나타냅니다. 정책 네트워크가 출력하는 정책 확률(prior_logits), 상태 가치(value), 그리고 상태를 표현하는 임베딩(embedding)을 포함합니다.recurrent_fn: 환경의 동역학 모델 역할을 하는 함수입니다. 현재 상태의embedding과 선택된action을 입력받아, 다음 상태의embedding과 함께 전이 과정에서 얻는 보상(reward), 할인율(discount), 그리고 다음 상태의 정책 확률과 가치를 반환합니다.
5.2. 환경 정의
상태 전이와 보상은 아래와 같이 정의되어 있습니다.
# We will define a deterministic toy environment.
# The deterministic `transition_matrix` has shape `[num_states, num_actions]`.
# The `transition_matrix[s, a]` holds the next state.
transition_matrix = jnp.array([
[1, 2, 3, 4],
[0, 5, 0, 0],
[0, 0, 0, 6],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
], dtype=jnp.int32)
# The `rewards` have shape `[num_states, num_actions]`. The `rewards[s, a]`
# holds the reward for that (s, a) pair.
rewards = jnp.array([
[1, -1, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[10, 0, 20, 0],
], dtype=jnp.float32)
총 7개의 상태가 있으며, transition_matrix는 상태 전이를, rewards는 각 행동에 대한 보상을 정의합니다.
또한 상태 가치에 대한 할인율도 정의되어 있습니다.
# The discount for each (s, a) pair.
discounts = jnp.where(transition_matrix > 0, 1.0, 0.0)
transition_matrix의 값이 0, 즉 다음 상태가 없는 경우 할인율이 0이 됩니다.
5.3. 상태 가치의 초기값
각 상태의 초기 가치는 15로 설정되어 있습니다. 이는 탐색 초기에 모든 상태를 낙관적으로 평가하여 탐험(exploration)을 장려하기 위함입니다.
# Using optimistic initial values to encourage exploration.
values = jnp.full([num_states], 15.0)
5.4. 정책 네트워크의 사전 확률
각 상태에서 정책 네트워크가 출력하는 사전 확률의 logits은 0으로 설정되어 있습니다. 이는 탐색 초기 단계에서 모든 행동이 동일한 확률을 갖도록 합니다.
# The prior policies for each state.
all_prior_logits = jnp.zeros_like(rewards)
5.5. 루트 노드와 상태 전이 함수 호출 예시
_make_batched_env_model 함수를 사용하여 루트 노드와 상태 전이 함수를 정의합니다.
def _make_batched_env_model(
batch_size: int,
*,
transition_matrix: chex.Array,
rewards: chex.Array,
discounts: chex.Array,
values: chex.Array,
prior_logits: chex.Array):
"""Returns a batched `(root, recurrent_fn)`."""
chex.assert_equal_shape([transition_matrix, rewards, discounts,
prior_logits])
num_states, num_actions = transition_matrix.shape
chex.assert_shape(values, [num_states])
# We will start the search at state zero.
root_state = 0
root = mctx.RootFnOutput(
prior_logits=jnp.full([batch_size, num_actions],
prior_logits[root_state]),
value=jnp.full([batch_size], values[root_state]),
# The embedding will hold the state index.
embedding=jnp.zeros([batch_size], dtype=jnp.int32),
)
def recurrent_fn(params, rng_key, action, embedding):
del params, rng_key
chex.assert_shape(action, [batch_size])
chex.assert_shape(embedding, [batch_size])
recurrent_fn_output = mctx.RecurrentFnOutput(
reward=rewards[embedding, action],
discount=discounts[embedding, action],
prior_logits=prior_logits[embedding],
value=values[embedding])
next_embedding = transition_matrix[embedding, action]
return recurrent_fn_output, next_embedding
return root, recurrent_fn
root, recurrent_fn = _make_batched_env_model(
# Using batch_size=2 to test the batched search.
batch_size=2,
transition_matrix=transition_matrix,
rewards=rewards,
discounts=discounts,
values=values,
prior_logits=all_prior_logits
)
루트 노드는 RootFnOutput 타입으로, 사전 확률, 가치, 상태 임베딩을 보유합니다.
MuZero에서는 이 임베딩이 상태를 표현하는 벡터가 되지만, 이 예제에서는 상태의 인덱스를 그대로 사용합니다.
상태 전이 함수 recurrent_fn은 현재 상태의 embedding과 선택된 action을 입력받아, 전이 과정에서 얻는 정보(RecurrentFnOutput)와 다음 상태의 embedding을 반환합니다.
배치 단위 탐색을 위해 각 데이터의 첫 번째 차원은 배치 크기가 됩니다.
5.6. gumbel_muzero_policy 호출 예시
visualization_demo.py에서는 위에서 정의한 구성 요소들을 gumbel_muzero_policy에 전달하여 탐색을 수행합니다.
# Running the search.
policy_output = mctx.gumbel_muzero_policy(
params=(),
rng_key=rng_key,
root=root,
recurrent_fn=recurrent_fn,
num_simulations=FLAGS.num_simulations,
max_depth=FLAGS.max_depth,
max_num_considered_actions=FLAGS.max_num_considered_actions,
)
인수는 rng_key, 루트 노드(root), 상태 전이 함수(recurrent_fn), 시뮬레이션 횟수(num_simulations), 탐색 깊이(max_depth), 루트 노드의 최대 행동 수(max_num_considered_actions)입니다.
참고로 rng_key는 난수를 생성하기 위해 사용됩니다.
탐색이 완료되면 policy_output 객체에 결과가 담겨 반환됩니다. policy_output.action은 탐색을 통해 결정된 최적의 행동을, policy_output.action_weights는 정책 네트워크 학습에 사용될 수 있는 목표 확률값을 담고 있습니다.
6. 🏁 마치며
이번 포스트에서는 Gumbel AlphaZero의 기본 개념과 그 기반이 되는 Mctx 라이브러리에 대해 알아보았습니다. Mctx의 설치 방법과 visualization_demo.py 예제를 통해 탐색 알고리즘이 어떤 구성 요소들을 필요로 하고 어떻게 동작하는지 살펴보았습니다.
다음 포스트에서는 Gumbel AlphaZero의 핵심이라 할 수 있는 행동 선택(Action Selection) 알고리즘, 특히 Gumbel-Top-k와 순차적 반감법에 대해 더 자세히 알아보겠습니다.