비동기 파이썬 기반 LLM API 구현: OpenAI API, Redis, Asyncio 활용
📑 Table Of Contents
- 1. ⚙ 비동기 LLM API의 개념
- 2. ⚙ OpenAI API 비동기 호출
- 3. ⚙ FastAPI 기반 비동기 LLM 서비스 설계
- 4. ⚙ Redis를 활용한 상태 관리 및 캐싱
- 5. ⚙ 전체 구조 및 코드 예시
- 6. ⚙ 고려사항 및 베스트 프랙티스
- 7. 🏁 마치며

1. ⚙ 비동기 LLM API의 개념
비동기 프로그래밍의 필요성
대규모 언어모델(LLM) API를 활용할 때, 다수의 프롬프트를 순차적으로 처리하면 네트워크 지연과 응답 대기 때문에 전체 처리 시간이 크게 늘어납니다.
비동기 프로그래밍을 적용하면 여러 요청을 동시에 처리할 수 있어 처리량(throughput)이 비약적으로 증가하고, 응답 대기 시간을 줄일 수 있습니다.
Python 비동기 기초와 Asyncio
Python의 asyncio 모듈은 코루틴, 이벤트 루프, Future 객체를 활용해 비동기 코드를 작성할 수 있게 해줍니다.
-
코루틴:
async def로 정의,await로 일시 중단 및 재개 -
이벤트 루프: 비동기 작업을 관리
-
awaitables:
await로 대기 가능한 객체 -
워커(Worker): 작업 큐에서 작업을 가져와 실행하는 소비자(consumer) 역할을 하는 비동기 함수로, 여러 워커가 동시에 실행되어 병렬 처리를 구현
import asyncio
async def greet(name):
await asyncio.sleep(1)
print(f"Hello, {name}!")
async def main():
await asyncio.gather(
greet("Kamil Lee"),
greet("parousia0918")
)
asyncio.run(main())
이처럼 여러 작업을 동시에 실행할 수 있습니다.
애플리케이션 다이어그램
해당 애플리케이션을 구현하기 위한 다이어그램은 아래와 같습니다. 전체적인 맥락을 파악하는 데 도움이 되시길 바랍니다.
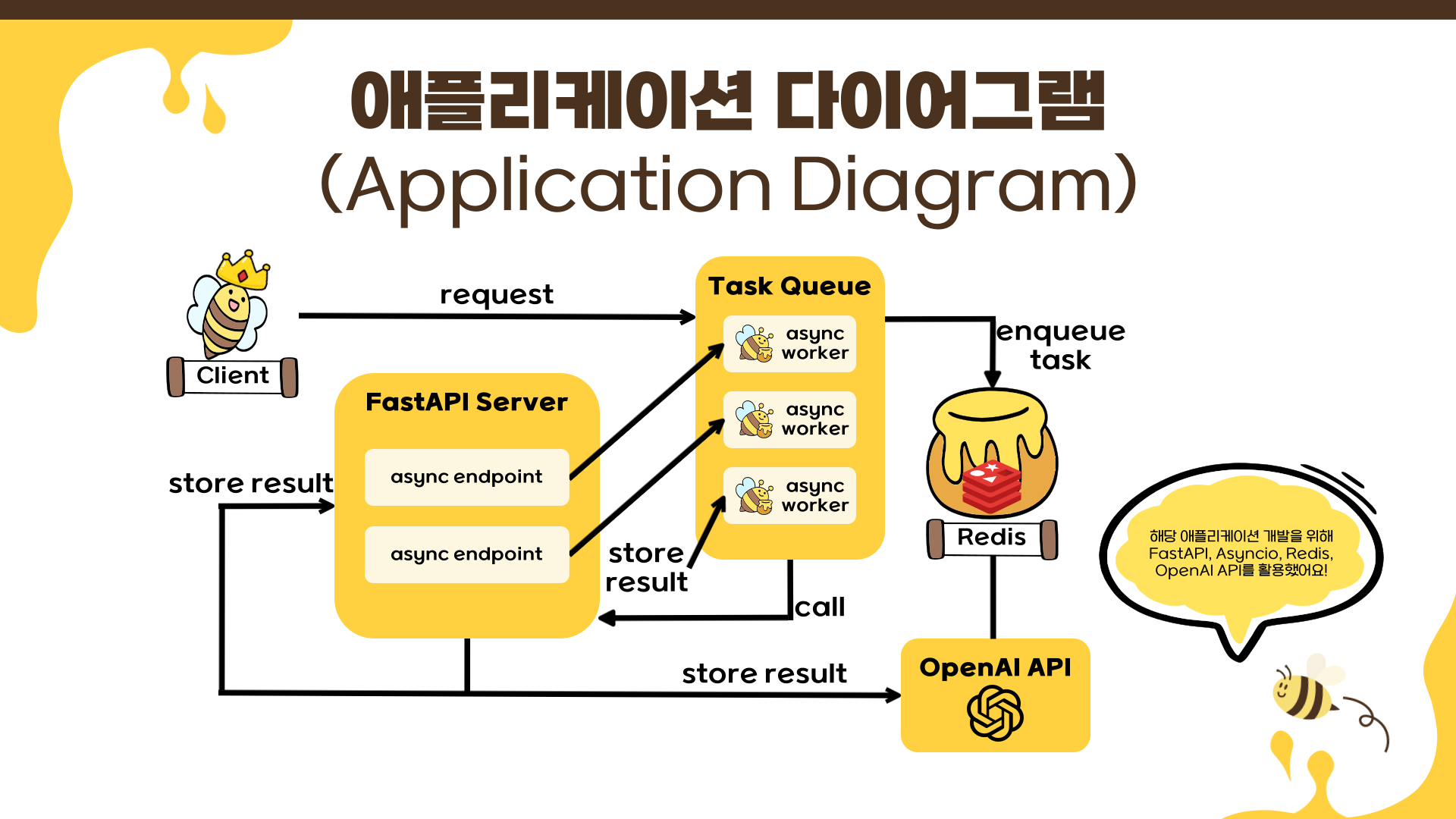
-
전체 아키텍처 개요: 이 다이어그램은 비동기 LLM API 시스템의 전체 워크플로우를 보여줍니다. 시스템은 이벤트 기반 비동기 처리를 통해 높은 처리량과 효율적인 자원 활용을 가능하게 합니다.
-
컴포넌트별 상세 분석
- Client(클라이언트): 클라이언트는 시스템의 진입점으로, 다음과 같은 역할을 수행합니다.
- 요청 전송: 여러 개의 프롬프트를 포함한 배치 요청을 FastAPI 서버로 전송
- 비동기 응답 처리: 즉시 task_id 목록을 받아 비동기적으로 결과 조회
- 폴링 또는 웹소켓: 작업 완료 상태를 주기적으로 확인하거나 실시간 알림 수신
- FastAPI Server(웹 서버): FastAPI 서버는 비동기 웹 프레임워크로서 핵심 역할을 수행합니다.
- async endpoint(비동기 엔드포인트)
POST /api/tasks: 프롬프트 배치를 받아 각각에 UUID 기반 task_id 할당GET /api/tasks: 쉼표로 구분된 task_id들의 상태 및 결과 조회Non-blocking I/O: 각 요청이 I/O 대기 중에도 다른 요청을 동시 처리
- 주요 특징
- Pydantic 통합: 자동 요청/응답 검증 및 직렬화
- Starlette 기반: ASGI 서버로 높은 동시성 지원
- lifespan 이벤트: 애플리케이션 시작/종료 시 자원 관리
- async endpoint(비동기 엔드포인트)
- Task Queue(작업 큐):
asyncio.Queue를 활용한 생산자-소비자 패턴의 핵심입니다.- 큐 동작 방식
- FIFO(First In, First Out): 먼저 들어온 작업부터 순차 처리
- 백프레셔 제어: 큐 크기 제한으로 메모리 사용량 조절
- 비동기 put/get: 큐 조작 시 이벤트 루프 블로킹 방지
-
enqueue task(작업 추가)
await task_queue.put((task_id, prompt))
- 큐 동작 방식
- Async Workers(비동기 워커들): 여러 워커가 동시에 실행되어 병렬 처리를 구현합니다.
- 워커 특징
- 고정 워커 풀: 시스템 자원에 맞게 워커 수 조절 (일반적으로 CPU 코어 x 2) 독립적 실행: 각 워커는 별도 코루틴으로 실행되어 서러 간섭하지 않음 Graceful 종료: 애플리케이션 종료 시 현재 작업 완료 후 안전하게 종료
-
워커 실행 흐름
async def background_worker(redis_client, task_queue): while True: task_id, prompt = await task_queue.get() await process_llm_task(redis_client, task_id, prompt) task_queue.task_done()
- 워커 특징
- Redis(상태 저장소): 비동기 클라이언트를 통한 상태 관리 및 캐싱
- 주요 기능
- 작업 상태 추적:
task:{task_id}키로 각 작업의 진행 상황 저장 - 결과 캐싱: 완료된 작업의 결과를 임시 저장
- TTL 관리: 자동 만료로 메모리 효율성 확보
- 작업 상태 추적:
-
상태 전이
queued -> processing -> completed/error -
store result(결과 저장)
await redis_client.hset(f"task:{task_id}", mapping={ "status": "completed", "result": llm_response, "timestamp": datetime.now().isoformat() })
- 주요 기능
- OpenAI API(외부 LLM 서비스):
AsyncOpenAI를 통한 비동기 API 호출- 비동기 호출의 장점
- 네트워크 대기 시간 활용: API 응답 대기 중 다른 작업 처리 가능
- 동시 요청 처리: 여러 프롬프트를 병렬로 OpenAI API에 전송
- 에러 격리: 개별 요청 실패가 전체 시스템에 영향을 주지 않음
- 비동기 호출의 장점
- Client(클라이언트): 클라이언트는 시스템의 진입점으로, 다음과 같은 역할을 수행합니다.
2. ⚙ OpenAI API 비동기 호출
AsyncOpenAI 활용
OpenAI 공식 Python 클라이언트는 비동기 사용을 지원합니다.
AsyncOpenAI와 같은 비동기 메서드를 사용하면 여러 프롬프트에 대한 응답을 병렬로 받을 수 있습니다.
# app/routers/router.py
from openai import AsyncOpenAI
# LLM 작업 처리 함수
async def process_llm_task(redis_client: redis.Redis, task_id: str, prompt: str):
"""LLM 작업 처리 함수"""
# ... Redis 설정 관련 생략 ...
try:
# ... Redis 상태 업데이트 관련 생략 ...
# OpenAI API 호출
client = AsyncOpenAI(api_key=os.getenv('OPENAI_API_KEY'))
try:
# OpenAI 공식 라이브러리의 최신 비동기 호출 방식을 사용
response = await client.chat.completions.create(
model="gpt-3.5-turbo", # GPT-3.5 Turbo 모델 사용
messages=[
{"role": "user", "content": prompt} # 메시지 형식 사용
],
max_tokens=100,
temperature=0.7,
timeout=30.0 # API 호출 타임아웃 설정 (초)
)
# ... 결과 파싱 및 Redis 상태 업데이트 관련 생략 ...
# 예외 처리
except Exception as e:
...
except Exception as e:
...
이 방식으로 여러 요청을 동시에 처리할 수 있습니다.
동시성/배치 처리
-
동시성 제어:
asyncio.Queue와 고정된 수의 워커(consumer)를 활용해, 큐에 쌓인 작업을 병렬로 처리합니다. 각 워커는 큐에서 작업을 가져와 비동기적으로 실행하는 독립적인 소비자(consumer)로, 워커 수를 적절히 조절함으로써 동시에 처리되는 작업 수를 제한할 수 있습니다. -
배치 처리: 단일 API 호출로 여러 프롬프트를 처리하는 것이 아닌, 다수의 개별 프롬프트 작업을 큐에 넣고 여러 워커가 이를 병렬로 처리하는 방식입니다. 이를 통해 많은 양의 작업을 보다 효율적으로 분산 처리할 수 있으며, 자원을 최적으로 활용할 수 있습니다.
3. ⚙ FastAPI 기반 비동기 LLM 서비스 설계
FastAPI는 파이썬 비동기 코드를 자연스럽게 지원하는 프레임워크이며, Starlette과 Pydantic을 기반으로 비동기 I/O의 장점을 최대한 활용할 수 있도록 설계되었습니다.
-
Non-blocking I/O: 전통적인 동기식 웹 서버와 달리, FastAPI는 각 요청이 I/O 작업을 기다리는 동안 다른 요청을 처리할 수 있어 동일 하드웨어에서 더 많은 동시 연결을 처리
-
이벤트 루프 활용: asyncio의 이벤트 루프를 기반으로 하여 대량의 동시 연결을 효율적으로 관리
-
비동기 라우팅: 라우트 핸들러를
async def로 정의하여 비동기 처리가 필요한 작업(외부 API 호출, DB 쿼리 등)을 효율적으로 처리
엔드포인트 설계 및 예시
FastAPI는 Python 비동기 코드를 자연스럽게 지원하는 프레임워크입니다.
POST /api/tasks: 여러 프롬프트를 받아 비동기 작업 생성, 각 작업에 고유 task_id 부여GET /api/tasks: 작업 상태(progress/result) 조회
# app/routers/router.py
@router.post("/tasks")
async def create_tasks(prompts: PromptList):
"""프롬프트 리스트를 큐에 추가하고 작업 ID를 반환하는 함수"""
task_ids = []
if not prompts or not prompts.prompts:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="프롬프트 리스트가 비어 있습니다.")
logger.info(f"{len(prompts.prompts)}개의 새 작업 생성 요청 수신")
for prompt in prompts.prompts:
task_id = str(uuid.uuid4())
# 큐에 작업 추가
await task_queue.put((task_id, prompt))
task_ids.append(task_id)
logger.debug(f"작업 {task_id} 큐에 추가됨")
logger.info(f"{len(task_ids)}개의 작업이 성공적으로 큐에 추가됨")
# 응답 시 상태를 'queued' 등으로 표시
return {"task_ids": task_ids, "status": "queued"}
@router.get("/tasks")
async def get_task_status(task_ids: str, request: Request) -> Dict[str, TaskStatus | Dict[str, str]]: # 응답 타입 힌트 개선
"""작업 상태를 반환하는 함수"""
logger.info(f"작업 상태 조회 요청 수신 (task_ids: {task_ids})")
# 쉼표로 구분된 작업 ID 리스트를 분리
task_id_list = [id.strip() for id in task_ids.split(",") if id.strip()]
if not task_id_list:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="유효한 작업 ID를 제공해야 합니다.")
res = {}
# Redis 클라이언트를 request.app.state에서 가져옵니다.
redis_client = request.app.state.redis_client
for task_id in task_id_list:
# Redis에서 작업 데이터 가져오기
try:
task_data = await redis_client.hgetall(f"task:{task_id}")
if task_data:
# TaskStatus 모델에 맞춰 데이터를 구성 (또는 원시 데이터 반환)
res[task_id] = TaskStatus(**task_data).model_dump() # Pydantic 모델 사용 예시
else:
# Redis에 작업 정보가 없는 경우
res[task_id] = {"status": "not_found"}
logger.debug(f"작업 {task_id} 상태 조회 결과: {res[task_id]}")
except ValidationError as e:
logger.warning(f"작업 {task_id}: TaskStatus 모델 검증 실패 - {e}")
res[task_id] = task_data # 원시 데이터 반환
except Exception as e:
logger.error(f"작업 {task_id} 상태 조회 중 Redis 오류 발생: {e}", exc_info=True)
res[task_id] = {"status": "error", "error": "Failed to retrieve status from Redis"}
return res
이 구조를 확장해 작업 큐, 상태 추적, 캐싱 등을 구현할 수 있습니다.
4. ⚙ Redis를 활용한 상태 관리 및 캐싱
비동기 Redis 클라이언트 활용
-
aioredis 또는 redis.asyncio를 사용하면 Redis와 비동기적으로 통신할 수 있습니다.
-
작업별 상태(progress/result) 저장 및 TTL(Time-To-Live)로 만료 관리
# app/main.py
from contextlib import asynccontextmanager
from dotenv import load_dotenv
from fastapi import FastAPI
import asyncio
import os
import redis.asyncio as redis
import logging
# ... 로깅, 환경변수 호출 등 생략 ...
@asynccontextmanager
async def lifespan(app: FastAPI):
"""애플리케이션 생명주기 관리 함수"""
logger.info("애플리케이션 시작: Redis 클라이언트 및 백그라운드 워커 초기화")
# Redis 클라이언트 초기화 및 상태에 저장
try:
app.state.redis_client = redis.Redis(
host=os.getenv('REDIS_HOST'),
port=int(os.getenv('REDIS_PORT', 6379)),
db=int(os.getenv('REDIS_DB', 0)),
decode_responses=True, # 문자열로 데이터를 처리
socket_connect_timeout=5,
socket_timeout=5,
retry_on_timeout=True
)
# Redis 연결 확인
await app.state.redis_client.ping()
logger.info("Redis 클라이언트 연결 성공")
except Exception as e:
logger.critical(f"Redis 클라이언트 초기화 또는 연결 실패: {e}", exc_info=True)
# Redis 연결 실패 시 애플리케이션 시작을 중단하거나,
# API 요청 시 Redis 연결 재시도 로직을 구현해야 합니다.
# 여기서는 로깅만 하고 애플리케이션은 계속 진행하도록 합니다.
# 프로덕션 환경에서는 더 견고한 처리가 필요할 수 있습니다.
raise e # 또는 적절한 fallback 로직 구현
# 백그라운드 워커 시작
from routers.router import background_worker, task_queue # router.py에서 가져옵니다.
for _ in range(NUM_WORKERS):
# asyncio.create_task를 사용하여 워커 코루틴을 스케줄링합니다.
task = asyncio.create_task(background_worker(app.state.redis_client, task_queue))
worker_tasks.append(task)
logger.info(f"{NUM_WORKERS}개의 백그라운드 워커 시작됨")
# yield를 통해 애플리케이션 구동
yield
# 애플리케이션 종료 시 정리 작업
logger.info("애플리케이션 종료: 백그라운드 워커 및 Redis 클라이언트 정리")
# 큐가 빌 때까지 기다리거나, 남은 작업을 취소할 수 있습니다.
# 여기서는 간단히 워커 태스크들을 취소합니다.
for task in worker_tasks:
task.cancel()
# 취소가 완료될 때까지 기다립니다.
await asyncio.gather(*worker_tasks, return_exceptions=True)
logger.info("백그라운드 워커 정리 완료")
# Redis 클라이언트 연결 종료
if hasattr(app.state, 'redis_client') and app.state.redis_client:
await app.state.redis_client.aclose()
logger.info("Redis 클라이언트 연결 종료")
# ... FastAPI 호출 및 main 함수 생략 ...
이처럼 작업별로 상태/결과를 저장하고 만료시킬 수 있습니다.
작업 상태 추적 및 TTL 관리
- 작업 생성 시 UUID로 task_id 생성, Redis에
status: pending저장 - 작업 완료 후
status: completed, 결과 저장 - TTL로 24시간 등 자동 만료 설정
- GET 엔드포인트에서 task_id로 상태/결과 조회
5. ⚙ 전체 구조 및 코드 예시
아래는 OpenAI API, FastAPI, Redis, Asyncio를 결합한 비동기 LLM API의 전체 구조 예시입니다. 이 시스템은 다음과 같은 비동기 워크플로우를 따릅니다.
- 클라이언트가
/api/tasks엔드포인트를 통해 프롬프트 목록 전송 - 각 프롬프트마다 고유 task_id 생성 후 비동기 큐에 추가
- 여러 워커(소비자)가 동시에 큐를 모니터링하며 작업 처리
- Redis를 통한 작업 상태 관리 및 결과 저장
- 클라이언트가
GET /api/tasks요청으로 작업 상태 및 결과 조회
이러한 구조는 I/O 바운드 작업(API 호출, DB 쿼리 등)을 효율적으로 병렬 처리하여, 시스템 자원을 최대한 활용하면서 높은 처리량을 제공합니다.
# app/routers/router.py
from fastapi import APIRouter, Request, HTTPException, status
from typing import Any, Dict, List, Union
from pydantic import BaseModel, ValidationError
from openai import AsyncOpenAI
from openai import APIStatusError, APIConnectionError, RateLimitError
import asyncio
import logging
import os
import uuid
import redis.asyncio as redis
logger = logging.getLogger(__name__)
router = APIRouter()
# 비동기 방식의 큐 구현
# 큐는 애플리케이션 시작 시 초기화되고, 워커들이 공유합니다.
task_queue = asyncio.Queue()
class PromptList(BaseModel):
"""PromptList 모델 클래스 정의"""
prompts: List[str] # 프롬프트 리스트
# 작업 상태 조회를 위한 모델 (Optional, Pydantic 응답 모델로 사용 가능)
class TaskStatus(BaseModel):
"""TaskStatus 모델 클래스 정의"""
status: str
result: Any = None
error: str = None
progress: str = None
# 백그라운드 워커 함수
async def background_worker(redis_client: redis.Redis, task_queue: asyncio.Queue):
"""백그라운드 워커 함수"""
logger.info("백그라운드 워커 시작 대기 중")
while True:
task_id, prompt = None, None # 예외 발생 시 로깅을 위해 초기화
try:
# 큐에서 작업 가져오기
task_id, prompt = await task_queue.get()
logger.info(f"작업 {task_id} 처리 시작")
# LLM 작업 처리 함수 호출
await process_llm_task(redis_client, task_id, prompt) # Redis 클라이언트를 인자로 전달
# 작업 완료를 큐에 알림
task_queue.task_done()
logger.info(f"작업 {task_id} 처리 완료")
except asyncio.CancelledError:
# 애플리케이션 종료 등으로 인해 태스크가 취소된 경우
logger.info("백그라운드 워커 취소됨")
break # 루프 종료
except Exception as error:
# 예상치 못한 다른 예외 발생 시
logger.error(f"백그라운드 워커 처리 중 예외 발생 (task_id: {task_id}): {error}", exc_info=True)
# 큐에서 작업을 제거하고 상태를 에러로 기록하는 것이 좋습니다.
if task_id:
try:
await redis_client.hset(
f"task:{task_id}",
mapping={
"status": "unexpected_worker_error",
"error": f"Worker exception: {error}"
}
)
except Exception as redis_err:
logger.error(f"예상치 못한 워커 에러 상태 업데이트 실패 (task_id: {task_id}): {redis_err}", exc_info=True)
# 큐에서 작업 완료 처리 (에러 발생 시에도 다음 작업을 가져와야 하므로 task_done 호출)
if task_id:
task_queue.task_done()
# 에러 발생 시 루프를 계속 진행하여 다음 작업을 처리
# 만약 복구 불가능한 에러라면 루프를 종료하거나 특정 로직을 수행할 수 있습니다.
continue
# LLM 작업 처리 함수
async def process_llm_task(redis_client: redis.Redis, task_id: str, prompt: str):
"""LLM 작업 처리 함수"""
logger.info(f"LLM 작업 처리 시작 (task_id: {task_id})")
# Redis 키 이름 상수화 (가독성 및 관리 용이성 향상)
TASK_REDIS_KEY = f"task:{task_id}"
# 작업 상태 및 결과 만료 시간 (초)
TASK_TTL_SECONDS = 86400 # 24시간
try:
# Redis 상태를 "processing"으로 업데이트
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "processing",
"progress": "0" # 프로그레스는 필요에 따라 업데이트
}
)
# TTL 설정 (키가 없으면 설정되지 않으므로, hset 이후에 호출)
await redis_client.expire(TASK_REDIS_KEY, TASK_TTL_SECONDS)
logger.debug(f"작업 {task_id}: Redis 상태 'processing' 업데이트 및 TTL 설정")
# OpenAI API 호출
client = AsyncOpenAI(api_key=os.getenv('OPENAI_API_KEY'))
logger.debug(f"작업 {task_id}: OpenAI API 호출 준비")
try:
# OpenAI 공식 라이브러리의 최신 비동기 호출 방식을 사용
response = await client.chat.completions.create(
model="gpt-3.5-turbo", # GPT-3.5 Turbo 모델 사용
messages=[
{"role": "user", "content": prompt} # 메시지 형식 사용
],
max_tokens=100,
temperature=0.7,
timeout=30.0 # API 호출 타임아웃 설정 (초)
)
logger.debug(f"작업 {task_id}: OpenAI API 응답 수신")
# 결과 파싱
if response.choices and response.choices[0].message:
result = response.choices[0].message.content
logger.debug(f"작업 {task_id}: 결과 추출 성공")
else:
result = "No content in response"
logger.warning(f"작업 {task_id}: OpenAI 응답에 결과 없음")
# 작업 결과 및 상태 업데이트
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "completed",
"result": result,
"progress": "100"
}
)
logger.info(f"작업 {task_id}: Redis 상태 'completed' 및 결과 업데이트")
# OpenAI 관련 예외 처리
except RateLimitError as e:
logger.warning(f"작업 {task_id}: OpenAI Rate Limit 초과 - {e}", exc_info=True)
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "error",
"error": f"Rate Limit Exceeded: {e}"
}
)
except APIStatusError as e:
# API 응답 상태 코드 오류
logger.error(f"작업 {task_id}: OpenAI API 상태 오류 (Status: {e.status_code}) - {e}", exc_info=True)
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "error",
"error": f"OpenAI API Status Error ({e.status_code}): {e.response.text}"
}
)
except APIConnectionError as e:
# 네트워크 또는 연결 오류
logger.error(f"작업 {task_id}: OpenAI API 연결 오류 - {e}", exc_info=True)
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "error",
"error": f"OpenAI API Connection Error: {e}"
}
)
except TimeoutError:
# asyncio 또는 http 라이브러리 레벨의 타임아웃
logger.error(f"작업 {task_id}: OpenAI API 호출 타임아웃", exc_info=True)
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "error",
"error": "OpenAI API Request timed out"
}
)
except Exception as e:
# 기타 OpenAI 관련 예외
logger.error(f"작업 {task_id}: 예측하지 못한 OpenAI API 관련 오류 - {e}", exc_info=True)
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "error",
"error": f"Unexpected OpenAI API Error: {e}"
}
)
except Exception as error:
# Redis 통신 오류 등 LLM API 호출 자체 이전/이후 오류
logger.critical(f"작업 {task_id}: 작업 처리 중 치명적 오류 발생 - {error}", exc_info=True)
try:
await redis_client.hset(
TASK_REDIS_KEY,
mapping={
"status": "critical_processing_error",
"error": f"Critical processing error: {error}"
}
)
except Exception as redis_err:
logger.error(f"작업 {task_id}: 치명적 오류 발생 후 Redis 상태 업데이트 실패: {redis_err}", exc_info=True)
@router.post("/tasks")
async def create_tasks(prompts: PromptList):
"""프롬프트 리스트를 큐에 추가하고 작업 ID를 반환하는 함수"""
task_ids = []
if not prompts or not prompts.prompts:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="프롬프트 리스트가 비어 있습니다.")
logger.info(f"{len(prompts.prompts)}개의 새 작업 생성 요청 수신")
for prompt in prompts.prompts:
task_id = str(uuid.uuid4())
# 큐에 작업 추가
await task_queue.put((task_id, prompt))
task_ids.append(task_id)
logger.debug(f"작업 {task_id} 큐에 추가됨")
logger.info(f"{len(task_ids)}개의 작업이 성공적으로 큐에 추가됨")
# 응답 시 상태를 'queued' 등으로 표시
return {"task_ids": task_ids, "status": "queued"}
@router.get("/tasks")
async def get_task_status(task_ids: str, request: Request) -> Dict[str, Union[TaskStatus, Dict[str, str]]]:
"""작업 상태를 반환하는 함수"""
logger.info(f"작업 상태 조회 요청 수신 (task_ids: {task_ids})")
# 쉼표로 구분된 작업 ID 리스트를 분리
task_id_list = [id.strip() for id in task_ids.split(",") if id.strip()]
if not task_id_list:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail="유효한 작업 ID를 제공해야 합니다.")
res = {}
# Redis 클라이언트를 request.app.state에서 가져옵니다.
redis_client = request.app.state.redis_client
for task_id in task_id_list:
# Redis에서 작업 데이터 가져오기
try:
task_data = await redis_client.hgetall(f"task:{task_id}")
if task_data:
# TaskStatus 모델에 맞춰 데이터를 구성 (또는 원시 데이터 반환)
res[task_id] = TaskStatus(**task_data).model_dump() # Pydantic 모델 사용 예시
# 또는 res[task_id] = task_data # 원시 데이터 반환
else:
# Redis에 작업 정보가 없는 경우
res[task_id] = {"status": "not_found"}
logger.debug(f"작업 {task_id} 상태 조회 결과: {res[task_id]}")
except Exception as e:
logger.error(f"작업 {task_id} 상태 조회 중 Redis 오류 발생: {e}", exc_info=True)
res[task_id] = {"status": "error", "error": "Failed to retrieve status from Redis"}
return res
# app/main.py
from contextlib import asynccontextmanager
from dotenv import load_dotenv
from fastapi import FastAPI
import asyncio
import multiprocessing
import os
import redis.asyncio as redis
import logging
# 로깅 설정
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 환경변수 로드
load_dotenv()
# 환경변수 검증 로직
required_env_vars = ['OPENAI_API_KEY', 'NUM_WORKERS', 'REDIS_HOST', 'REDIS_PORT', 'REDIS_DB']
missing_vars = [var for var in required_env_vars if not os.getenv(var)]
if missing_vars:
raise ValueError(f"필수 환경변수가 설정되지 않았습니다: {missing_vars}")
# 백그라운드 워커 태스크 리스트
worker_tasks: list[asyncio.Task] = []
# 동적인 워커 수 설정 (asyncio 워커 수를 의미)
NUM_WORKERS = int(os.getenv('NUM_WORKERS', multiprocessing.cpu_count() * 2))
@asynccontextmanager
async def lifespan(app: FastAPI):
"""애플리케이션 생명주기 관리 함수"""
logger.info("애플리케이션 시작: Redis 클라이언트 및 백그라운드 워커 초기화")
# Redis 클라이언트 초기화 및 상태에 저장
try:
app.state.redis_client = redis.Redis(
host=os.getenv('REDIS_HOST'),
port=os.getenv('REDIS_PORT'),
db=os.getenv('REDIS_DB'),
decode_responses=True, # 문자열로 데이터를 처리
)
# Redis 연결 확인
await app.state.redis_client.ping()
logger.info("Redis 클라이언트 연결 성공")
except Exception as e:
logger.critical(f"Redis 클라이언트 초기화 또는 연결 실패: {e}", exc_info=True)
# Redis 연결 실패 시 애플리케이션 시작을 중단하거나,
# API 요청 시 Redis 연결 재시도 로직을 구현해야 합니다.
# 여기서는 로깅만 하고 애플리케이션은 계속 진행하도록 합니다.
# 프로덕션 환경에서는 더 견고한 처리가 필요할 수 있습니다.
raise e # 또는 적절한 fallback 로직 구현
# 백그라운드 워커 시작
from routers.router import background_worker, task_queue # router.py에서 가져옵니다.
for _ in range(NUM_WORKERS):
# asyncio.create_task를 사용하여 워커 코루틴을 스케줄링합니다.
task = asyncio.create_task(background_worker(app.state.redis_client, task_queue))
worker_tasks.append(task)
logger.info(f"{NUM_WORKERS}개의 백그라운드 워커 시작됨")
# yield를 통해 애플리케이션 구동
yield
# 애플리케이션 종료 시 정리 작업
logger.info("애플리케이션 종료: 백그라운드 워커 및 Redis 클라이언트 정리")
# 큐가 빌 때까지 기다리거나, 남은 작업을 취소할 수 있습니다.
# 여기서는 간단히 워커 태스크들을 취소합니다.
for task in worker_tasks:
task.cancel()
# 취소가 완료될 때까지 기다립니다.
await asyncio.gather(*worker_tasks, return_exceptions=True)
logger.info("백그라운드 워커 정리 완료")
# Redis 클라이언트 연결 종료
if hasattr(app.state, 'redis_client') and app.state.redis_client:
await app.state.redis_client.aclose()
logger.info("Redis 클라이언트 연결 종료")
# FastAPI 애플리케이션 초기화
app = FastAPI(
title="Asynchronous LLM API",
description="비동기 LLM 처리를 위한 API 서버",
version="1.0.0",
swagger_ui_parameters={
"syntaxHighlight": {
"theme": "obsidian"
}
},
lifespan=lifespan, # lifespan 함수 등록
)
# 라우터 등록
# routers.router 파일에서 정의된 router 객체를 가져옵니다.
from routers.router import router
app.include_router(router, prefix="/api", tags=["LLM Background"])
# 이 부분은 uvicorn 실행 시 필요합니다.
if __name__ == "__main__":
import uvicorn
# 로깅 설정을 lifespan이나 이 부분에서 일괄적으로 관리하는 것이 좋습니다.
uvicorn.run("main:app", host="localhost", port=8000, log_level="info") # uvicorn 로깅 레벨 설정
POST /api/tasks로 여러 프롬프트를 비동기 처리 요청- 각 작업은 별도 task_id로 Redis에 상태 저장
GET /api/tasks/{task_id}로 상태/결과 조회- Redis TTL로 자동 만료
6. ⚙ 고려사항 및 베스트 프랙티스
- 동시성 제어:
asyncio.Queue와 고정된 수의 워커를 통해 동시에 처리되는 작업의 수를 제한- 시스템 리소스에 맞게
NUM_WORKERS값 최적화 (일반적으로 CPU 코어 수 × 2 정도로 시작) - 워커 수가 많으면 동시성은 높아지나 CPU 오버헤드 발생, 적으면 큐 대기 시간 증가
- 에러 처리:
- LLM API 호출 관련 오류(토큰 한도 초과, 모델 로드 실패 등)에 대해 세분화된 예외 처리
- Redis 연결 실패 시 지수 백오프 전략으로 재시도 구현
- 치명적 오류 시 경고 알림 시스템 연동
- 캐싱 전략:
- 동일 프롬프트에 대한 결과 해시 기반 캐싱으로 중복 요청 방지
- 캐시 적중률 모니터링 및 최적화
- 캐시 무효화 주기 설정
- 작업 만료(TTL):
- Redis TTL 계층화: 작업 상태는 짧게(24시간), 결과는 길게(7일) 유지
- 중요 작업 결과 영구 저장소 연동
- 로깅/모니터링:
- Prometheus/Grafana로 큐 길이, 처리 시간, 오류율 등 실시간 모니터링
- 구조화된 로그로 디버깅 용이성 향상
- 평균 응답 시간, P95/P99 지연 시간 등 성능 지표 추적
- 부하 테스트 및 스케일링:
- 최대 부하 테스트로 시스템 한계 파악
- 필요시 Redis Cluster 구성으로 수평적 확장
- 급격한 트래픽 증가에 대비한 동적 워커 스케일링 구현
- 백그라운드 워커 관리:
- 애플리케이션 시작 시 워커 초기화:
/api/tasks엔드포인트 첫 호출 시가 아닌, FastAPI의lifespan이벤트 등을 활용하여 애플리케이션 시작과 함께 백그라운드 워커 코루틴들을 미리 생성하고 실행하는 것이 안정적입니다. - 워커의 Graceful shutdown: 애플리케이션 종료 시 실행 중인 워커들이 현재 작업을 완료하거나 안전하게 종료되도록 처리 로직을 구현해야 합니다.
- 애플리케이션 시작 시 워커 초기화:
- Redis 클라이언트 일관성:
- 애플리케이션 라이프사이클 관리(
lifespan)를 통해 초기화된 단일 비동기 Redis 클라이언트 인스턴스를 사용하여, 모든 Redis 접근(API 엔드포인트 및 백그라운드 워커)에서 일관성을 유지하고 클라이언트 리소스를 효율적으로 관리하는 것이 권장됩니다.
- 애플리케이션 라이프사이클 관리(
7. 🏁 마치며
비동기 파이썬, FastAPI, Redis, Asyncio, 그리고 OpenAI API를 결합하면 대규모 LLM 기반 API를 효율적으로 설계할 수 있습니다.
-
동시성을 통한 빠른 처리
-
Redis로 작업 상태 추적 및 캐싱
-
FastAPI로 확장성 높은 API 제공
-
Asyncio로 네트워크/IO 병목 최소화
이 구조는 의미 검색, 문서 요약, 질의응답 등 다양한 LLM 기반 서비스에 적용할 수 있으며, 대량 요청 처리와 실시간 응답이 중요한 환경에서 특히 강력한 선택지입니다.